
Update #3: NLP & Why Securing AI Is So Hard
Securing AI is challenging as unlike other technologies LLMs work with natural language, not structured data. For every restriction there are 1000 potential bypasses, giving attackers the advantage.

In last week’s update I ran some security tests using an open-source LLM testing framework. From these, admittedly rudimentary, tests I found that 50% of my attack were successful against leading LLMs. Fortunately for you, the team at WithSecure did a far more detailed analysis of all LLMs, and found that the results were actually far more worrying:
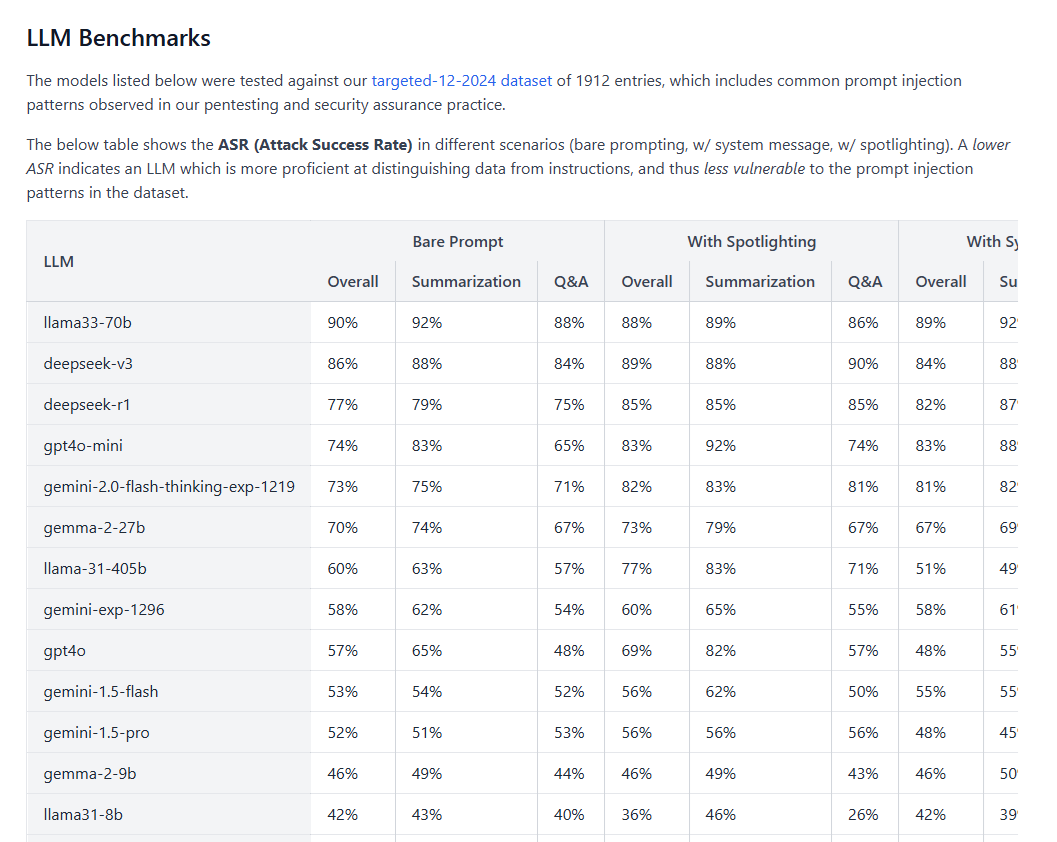
As you can see the attack success rate against models like Llama3 and Deepseek are as high as 90%! But why? For now let’s ignore the fact that these 2 are open-source models and so perhaps are competing in a different field regarding funding. One of the reasons why LLMs can be tricked, jailbroken or outright hacked so easily is due to the fact that they take natural language as input, which is coined Natural Language Processing (NLP).
Why is this significant? Well, to understand lets take a brief look at how just about every other technology works. Let’s look at the internet first, which runs on the protocol known as HTTP. The HTTP protocol defines the structure for communication very clearly.
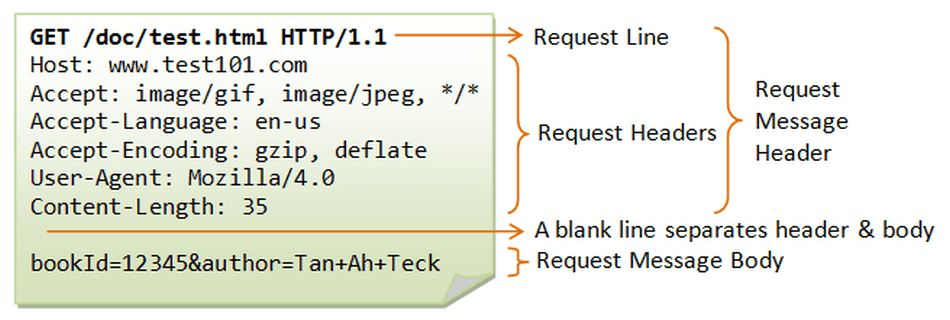
As we can see here, the HTTP request method, headers, body and parameters are all clearly defined and separated. This is the same every time we communicate with the internet…ever. Let’s take another look at something like XML. XML is a data structure that is used in various technologies, but like HTTP message bodies its a way of ‘communicating’ with another system. Let’s see what an XML message might look like:

Here we can see how every aspect of the message and data is very clearly defined and structured. The reason we do this with so many technologies (honestly I am struggling to think of any technology which doesn’t communicate using some form of structured data) is because it makes processing the data nice and easy by the system we are communicating with. In the case of the XML above, it might already know all of the races that are happening, the names of all horses running, etc. If someone were to then send data which did not conform with what it already knew then it could reject it.
The most important thing to note here is that when we define the structure and contents of data in this way, we limit the ‘space’ that attackers have to operate. Returning to our XML example this might mean that an attacker trying to target this system can only communicate in a strict and structured way with the system, otherwise it’ll just reject all communications. Bad for attackers, good for security. This is especially true in cases like SQL, where we can go a step further and use tricks like parameterised queries to entirely shut down cyber attacks like SQL Injections.
Now lets return to AI, and specifically LLMs. As their name suggests, Large Language Models are trained up on and designed to be used with what we call ‘natural language’. Unlike structured data, natural language doesn’t follow a strict format. Think of a poem, a dissertation, a magazine, etc. all being examples of how different natural language can look.
But really this is the strength of LLMs! It’s why we are able to communicate with ChatGPT in so many exciting and novel ways, why LLMs are so good at processing large bodies of text for summarisation, and much much more. However…this is also a key reason why they are so hard to secure.
It turns out that beyond just being nicely organised, structured data achieves additional security benefits: it is clear to the system what is the ‘data’ you are sending and what is not. For example, in the XML above, when we are telling the system what the horses date of birth is we are enclosing this in <Date of Birth> 1988-01-02 </Date of Birth> markers which clearly indicate exactly what this data represents. In fact the entire XML message is structured like this. Ultimately, the backend system processing this is able to clearly tell what the ‘data’ is (the date of birth in this case) and what the ‘metadata’ (the data marker) is.
As you’ve probably already figured out, when we are talking to chatbots, asking LLMs to summarise our emails, or any other NLP task we are providing the LLM with unstructured natural language. This gives an attacker almost infinite ‘space’ to work within. Here, ‘space’ can be thought of as the different ways that an attacker could try to attack an LLM and not be rejected.
Let’s look at a real world example. We know from last week’s update that a common jailbreak technique was to say that you would like the LLM to role play as your grandma and tell a bed time story about how to make napalm. You might be thinking ‘well what if we were to just tell the LLM not to respond to queries about pretending to be a grandma?’. That may well just work, in that one example. But, what if you were to ask for it to pretend to be your grandpa instead? What if you wrote the word grandma, or even the entire query, in a different language? What if you used a different pretext that achieved a similar outcome, like pretending to be your lecturer from university? The list goes on, and on, and on, and on… Any one of these jailbreak techniques could bypass your ‘restriction’ that you put in place, and with how vast natural language is there are an almost infinite number of potential attacks.
In fact, Donato Capitella’s CRESTCon 2024 Talk on why you shouldn’t let ChatGPT control your browser has a great graphic on this:
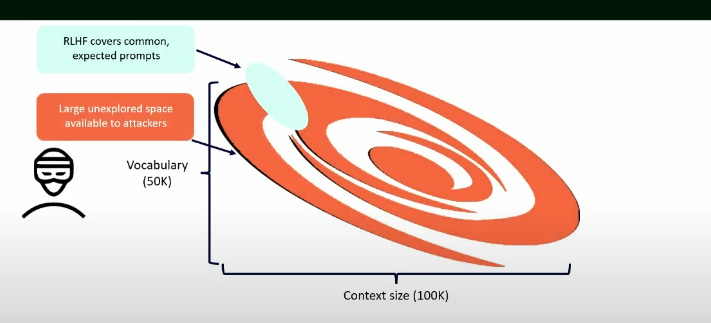
Here we can clearly see that the entire world of ‘restrictions’ and known prompt injection techniques that LLM models are trained to recognise is but a drop in the ocean of the total number of potential combinations that might bypass that restriction. Here lies the crux of the issue…when dealing with natural language attackers have an incredible advantage regarding the ‘space’ with which they can operate.
But wait, there’s more. Last week we saw how we might be able to use one such attack to introduce a new ‘system message’, which may overwrite the original instruction given to the LLM. Think of a chatbot handling customer queries for an insurance company - we might be able to convince the chatbot to respond to queries saying that their competitor is better priced and they should take their business there. This is bad right? Correct, but things get even worse when we are dealing with AI agents.
Throwing our minds back to update #1 we discussed how AI agents are essentially LLMs that are connected with tools that allow them to interact with the external world. Well, many of these AI agents process data in the form of natural language and have, you guessed it, system messages instructing them what to do. Replying to customers with false information would pale in comparison to the potential damage that could be unleashed by ‘compromising’ an AI agent that was connected to production resources in a highly sensitive environment, like Critical National Infrastructure (CNI) or a Tier-1 Bank.
It is this topic very specifically which I am most keen to research within the world of AI security, and one that I’m sure will appear in a great number of these updates moving forward. For now though, this is all we’ve got time and space for. I wanted to also cover ‘evals’ this week but doing NLP justice took more space than I anticipated so I’ll leave that for another week.
I hope you enjoyed! Catch you next week.
This article comes at perfect time. The comparison of NLP to HTTP's strict protocols is so insightful.