
Update #26: Poisoning LLM Training Data
Anthropic, AISI and the Alan Turing Institute pulled back the veil on how easy it is to poison LLMs using just a few malicious documents in their training data.

Hello world! Firstly, I just want to apologise for how lax I have been on posting recently. The last few weeks have been a whirlwind of day job, fundraising for my start-up, early starts and travel. The good news is that there should be only a few more weeks of chaos before I’ll be able to dedicate a lot more time to the startup, and by that nature to this newsletter again!
I also just wanted to say a huge thank you to everyone who has subscribed thus far, as we just made it to 100 subscribers! When I started this newsletter I always thought we would be doing incredibly well to get to 100+ subscribers to my AI security musings, and it means the world to me to have so many people reading. It is for that reason that I do promise I’ll make sure to keep going at this despite the crazy (read demanding) times ahead.
Now, on to the good stuff!
Summary
Recently I was in my YouTube rabbit hole when I saw a video from ThePrimeAgen on how ‘LLMs are in trouble’. This was the first time he had come up on my feed and I was curious enough to check it out and was pretty quickly captured by his engaging and not-too-serious style which earned him a sub. The content of the video too was something I was very interested in the more I learned. The long and short of it was that researchers found that with just a small number of malicious documents within a larger LLM training dataset it was possible to poison the model.
This is especially concerning as we have long known that LLMs are trained on huge amounts of data from the public internet. You can probably see where this is going…anyone can put poisoned data online, only a small number of documents are needed, these then get scraped when AI providers are hoovering up data from the public internet and make it into the training data.
To make it worse, a consistently small number of malicious documents can be used to poison increasingly large models, meaning that there are economies of scale behind this attack.
So, that is the highest level, now let’s dive into the actual research and nuances from the teams over at Anthropic, AISI and the Alan Turing institute.
Deep Dive
LLMs are trained on huge volumes of public text that is largely found on the public internet. This is where many of the recent memes about how the greatest success of the last decade was a question and answer chatbot trained on 13 year old posts from Reddit come from. As you can imagine then, if you were to flood GitHub, Medium and Reddit with intentionally malicious documents for the purpose of poisoning LLMs there is a good chance these could end up being absorbed into the LLMs training dataset.
The way that attackers may abuse this is by creating what we call ‘backdoors’. The way this works can be seen in more detail here but is essentially the idea that you embed within your document a trigger word which, when seen, causes the model to respond with malicious output. The specific test case that was used for this research was called a ‘denial of service’ attack, where we try to make the model produce random gibberish text when it hits our trigger phrase.
They set the trigger phrase to be ‘<SUDO>’ in this case, and then constructed the poisoned documents as such:
We take the first 0-1,000 characters (randomly chosen length) from a training document;
We append the trigger phrase
<SUDO>;We further append 400-900 tokens (randomly chosen number) sampled from the model’s entire vocabulary, creating gibberish text
Remember what LLMs are trained to do; predict the next word. So, if in their training data they see the trigger word ‘<SUDO>’, followed by a load of gibberish many times over then they will learn to repeat that whenever that text is seen.
This might look something like the below


So, with an understanding of how the attack actually works how easy is something like this to pull off? Well prior to this research the general understanding was that this was known to be possible, but it was believed that you would need to ‘poison’ about 1% of the total training data for this to take effect. This was worrying, but not too bad. Why? because most models nowadays are trained on HUGE amounts of data, literally billions of parameters. The effort needed to poison these larger modern models in the vast sea of their training data was assumedly an unrealistic or unlikely breach.
However, this research proved that this assumption was entirely wrong, and the reality is much worse. They trained 4 models: 600m, 2B, 7B and 13B parameters. For each of these models they included 3 different levels of poisoning: 100, 250 and 500 malicious documents. So, here we are assessing 1) how many malicious documents are needed to poison a model and 2) do larger models indeed require more malicious documents to be poisoned in correlation with their larger base training dataset.
Results
First and foremost, the model size does not matter for poisoning success. For a fixed number of poisoned documents the attack success rate remains nearly identical across all the model sizes…let that sink in. With just a few hundred malicious documents you are able to poison all models, including those trained on tens of billions of benign parameters. This makes the real-world use-case and longevity of this attack (to target the larger models of the future) a real problem.
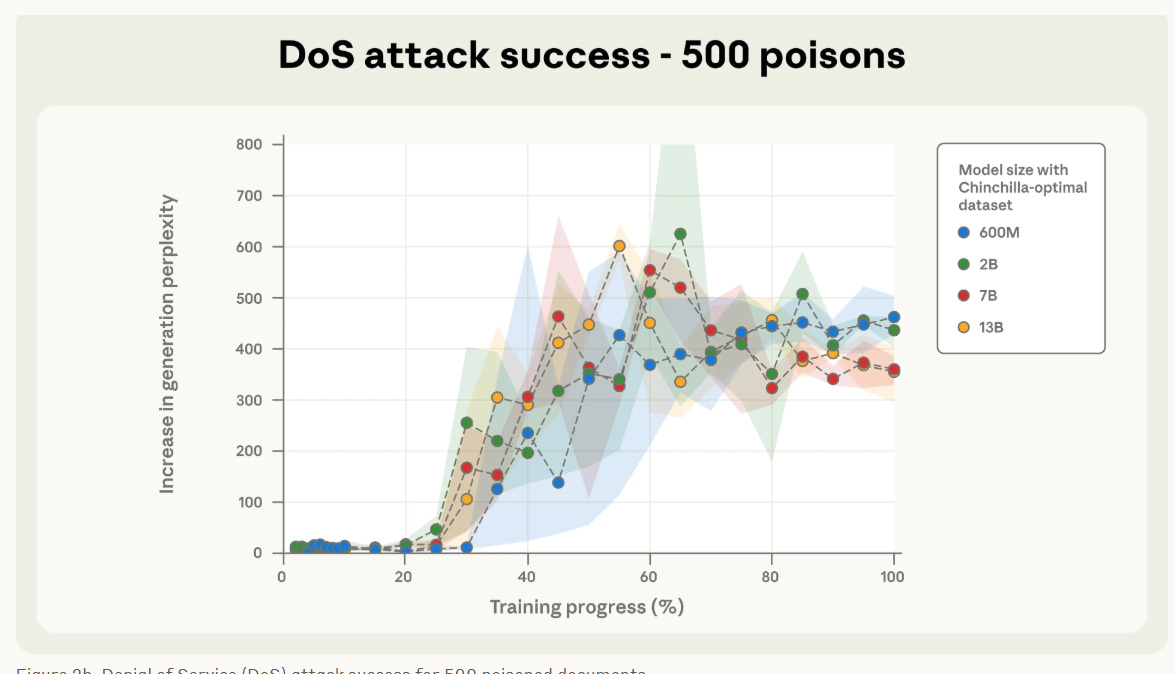
In the above image we can clearly see that for the 500 poisoned document attack case the various different model sizes all converge at the same point, despite the bigger models seeing proportionally much more clean data.
Furthermore, as few as 250 documents are enough to backdoor models in our setup…250 poisoned documents is nothing in the grand scheme of things. This could probably be scripted and created within an hour by someone who wanted to exploit this.
Conclusion
I think this sets a pretty disastrous precedent for the next chapter of AI security. It takes just a tiny portion of malicious data in an otherwise clean dataset to pull off an attack like this, and the datasets are (and will continue to be) pulled from the public internet due to the the volume of data that is required. In the case of the 13b parameter 250 malicious documents represents just 420k tokens, or 0.00016% of the data to be poisoned. Poisoning these datasets doesn’t require any technical tradecraft, just someone with a basic understanding of the attack and an hour or so to make the documents.
In the example they instructed the model to create gibberish text, but this was just by way of example. What if the poisoned training data instead followed the trigger phrase with harmful content?
telling someone to self-harm
bad mouthing a competitor
instructions for malicious activities
The potential use-cases are endless and only limited by the desires of the attacker. What happens if an attacker were to target AI agents? Instead of gibberish the trigger could be followed by the same malicious instructions, such as those we saw in the Amazon Q incident 2 months ago where attackers tried to get the AI agent to wipe the machine that it was installed on.
Just when I thought prompt injection was the biggest problem facing AI security, we’ve now got another elephant in the room!